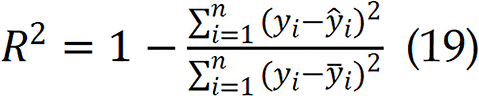Ding L, Peng JX, Song YJ. Deep learning approaches for image-based snoring sound analysis in the diagnosis of obstructive sleep apnea-hypopnea syndrome: A systematic review. World J Radiol 2025; 17(9): 109116 [PMID: 41025059 DOI: 10.4329/wjr.v17.i9.109116]
Corresponding Author of This Article
Jian-Xin Peng, Professor, School of Physics and Optoelectronics, South China University of Technology, No. 381 Wushan Road, Tianhe District, Guangzhou 510640, Guangdong Province, China. phjxpeng@163.com
Research Domain of This Article
Engineering, Biomedical
Article-Type of This Article
research-article
Open-Access Policy of This Article
This article is an open-access article which was selected by an in-house editor and fully peer-reviewed by external reviewers. It is distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/
Baishideng Publishing Group Inc, 7041 Koll Center Parkway, Suite 160, Pleasanton, CA 94566, USA
Share the Article
Ding L, Peng JX, Song YJ. Deep learning approaches for image-based snoring sound analysis in the diagnosis of obstructive sleep apnea-hypopnea syndrome: A systematic review. World J Radiol 2025; 17(9): 109116 [PMID: 41025059 DOI: 10.4329/wjr.v17.i9.109116]
Author contributions: Peng JX, Ding L designed the research study; Song YJ, Ding L performed the literature review and conducted the data analysis; Ding L wrote the manuscript.
Supported by the National Natural Science Foundation of China, No. 11974121; and Talent Research Fund of Hefei University, No. 24RC08.
Conflict-of-interest statement: The authors declare no conflicts of interest related to this work.
PRISMA 2009 Checklist statement: The authors have read the PRISMA 2009 Checklist, and the manuscript was prepared and revised according to the PRISMA 2009 Checklist.
Corresponding author: Jian-Xin Peng, Professor, School of Physics and Optoelectronics, South China University of Technology, No. 381 Wushan Road, Tianhe District, Guangzhou 510640, Guangdong Province, China. phjxpeng@163.com
Received: April 30, 2025 Revised: May 31, 2025 Accepted: August 13, 2025 Published online: September 28, 2025 Processing time: 150 Days and 4.4 Hours
Abstract
BACKGROUND
Obstructive sleep apnea-hypopnea syndrome (OSAHS) is a highly prevalent sleep-related respiratory disorder associated with serious health risks. Although polysomnography is the clinical gold standard for diagnosis, it is expensive, inconvenient, and unsuitable for population-level screening due to the need for professional scoring and overnight monitoring.
AIM
To address these limitations, this review aims to systematically analyze recent advances in deep learning–based OSAHS detection methods using snoring sounds, particularly focusing on graphical signal representations and network architectures.
METHODS
A comprehensive literature search was conducted following the PRISMA 2009 guidelines, covering publications from 2010 to 2025. Studies were included based on predefined criteria involving the use of deep learning models on snoring sounds transformed into graphical representations such as spectrograms and scalograms. A total of 14 studies were selected for in-depth analysis.
RESULTS
This review summarizes the types of signal modalities, datasets, feature extraction methods, and classification frameworks used in the current literatures. The strengths and limitations of different deep network architectures are evaluated.
CONCLUSION
Challenges such as dataset variability, generalizability, model interpretability, and deployment feasibility are also discussed. Future directions highlight the importance of explainable artificial intelligence and domain-adaptive learning for clinically viable OSAHS diagnostic tools.
Core Tip: This systematic review summarizes recent advances in the use of image-based deep learning models for snoring sound analysis in the diagnosis of obstructive sleep apnea-hypopnea syndrome (OSAHS). The review highlights the role of time–frequency representations and deep learning architectures in classifying snoring types and estimating severity of OSAHS. The work also identifies current challenges in data standardization, model interpretability, and clinical integration, providing direction for future research.
Citation: Ding L, Peng JX, Song YJ. Deep learning approaches for image-based snoring sound analysis in the diagnosis of obstructive sleep apnea-hypopnea syndrome: A systematic review. World J Radiol 2025; 17(9): 109116
Obstructive sleep apnea-hypopnea syndrome (OSAHS) is a highly prevalent and underdiagnosed sleep disorder that significantly impacts global public health[1-4]. Epidemiological studies find that moderate to severe OSAHS affects nearly 1 billion individuals aged 30–69 worldwide, with prevalence rates exceeding 50% in some countries[5,6]. During sleep, patients experience frequent partial or complete collapse of the upper airway, resulting in hypopnea or apnea events that disrupt normal respiration. Hypopnea is defined as a ≥ 30% drop in the flow signal for at least 10 s associated with either a ≥ 3% oxygen desaturation or arousal, while apnea is scored as a drop in the peak thermal sensor excursion by ≥ 90% of baseline for at least 10 s. The frequent apnea-hypopnea events significantly disrupted the sleep architecture of OSAHS patients at night. Clinically, OSAHS patients suffer oxygen desaturation, airflow obstruction, snoring, arousal during sleep, and excessive daytime sleepiness. Moreover, OSAHS has been strongly associated with increased risks of hypertension, cardiovascular disease, type 2 diabetes, cognitive impairment, and stroke[7-9]. The severity of OSAHS is typically assessed using the apnea-hypopnea index (AHI), which quantifies the average number of apnea and hypopnea events per hour of sleep. Based on AHI, OSAHS is classified as mild (5–15), moderate (15–30), and severe (> 30). Currently, the gold standards for clinical diagnosis of OSAHS is polysomnography (PSG), which uses multiple connected sensors to monitor various physiological signals during sleep, including electroencephalography, blood oxygen saturation, oral-nasal airflow, thoracoabdominal movement, and snoring sound. A trained otolaryngologist manually verifies the PSG recordings and makes the diagnostic assessment. The PSG remains costly, time-consuming, and often inaccessible to the general population, especially in primary care and low-resource settings[10,11].
Given these limitations of PSG, recent researches have been focused on exploring an alternative system to screening sleep and diagnosing OSAHS which is non-invasive, cost-effective, and scalable[12,13]. Snoring sound analysis has emerged as a promising direction. Snoring, a hallmark symptom of OSAHS, results from airflow-induced vibration of soft tissues in the upper airway[12-15]. Since the generation of snoring sounds has strong correlation with OSAHS, its acoustic signature encodes physiological changes related to obstruction severity, frequency, and pattern of respiratory events. Previous studies have shown that analysis of snoring sounds can achieve relatively high sensitivity and specificity in OSAHS diagnosis[13,15,16]. Early studies mainly focus on handcraft features combined with machine learning. These studies offer preliminary evidence of a relationship between characteristics of snoring sounds and OSAHS severity. However, the construction of feature sets is the key step, which greatly influences the diagnostic results. With the development of computer science and artificial intelligence, deep learning, a subfield of machine learning, has achieved remarkable success in processing high-dimensional data such as image, audio, and video. Deep learning models have been widely applied to analyze snoring sounds to enhance the OSAHS diagnosis performance, especially in real-world and noisy environments. Based on deep learning strategy, deep neural network (DNN) and convolutional neural network (CNN), recurrent neural network (RNN) have been mostly applied on the analysis of snoring sounds. DNNs, combined with linear and nonlinear handcraft feature sets, have been extensively applied on snoring sounds processing tasks due to their superior ability to learn complex nonlinear mappings. CNNs have become the dominant architecture for analyzing image-like representation of acoustic signals, due to their strong capability in local feature extraction and spatial patten recognition. CNNs have been widely adopted to process snoring-related acoustic features in the form of time-frequency images, including spectrograms, Mel-spectrograms, and scalograms. This paradigm shifts bridges acoustic signal processing with visual deep learning, enabling advanced feature extraction, robust classification, and even apnea severity estimation through end-to-end frameworks. Compared to traditional handcrafted feature methods, these graphical pipelines offer better scalability, adaptability to device heterogeneity, and stronger generalization across populations[16-18].
Existing reviews primarily focus on physiological signals [e.g., Electrocardiogram (ECG), SpO2] or general sleep monitoring systems, without addressing the unique advantages and challenges of visual-acoustic modeling[19-21]. Despite significant progress in this field, a comprehensive synthesis of image-based snoring sound diagnostics for OSAHS has yet to be formally conducted. Therefore, this review aims to systematically examine recent advances in the use of image-transformed snoring signals for OSAHS detection, classify the types of graphical features and deep learning architectures applied to provide in-depth knowledge about the application of deep learning in the diagnosis of OSAHS.
A systematic review is conducted following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) methodology. The review framework and literature selection criteria, snoring sound datasets, graphical transformation methods utilized for image-based modeling, and in-depth explanation of deep learning architectures are detailed in Section MATERIALS AND METHODS. The experimental results across different graphical inputs and model structures are systematically compared in Section RESULTS. Finally, Section DISCUSSION and CONCLUSION discusses and summaries the key challenges encountered in this domain, including dataset limitations, model generalization, interpretability, and real-world deployment, and outlines potential future research directions aimed at advancing the field of snoring-based OSAHS diagnostic systems.
MATERIALS AND METHODS
This review was conducted in accordance with the PRISMA 2009 guidelines to ensure methodological rigor and transparency. The goal was to identify and synthesize relevant literature focusing on the use of image-based snoring sound features for the diagnosis or classification of OSAHS based on deep learning techniques. A comprehensive and systematic search strategy was adopted to capture relevant studies published between January 2010 and March 2025. The literature search was carried out across five major scientific databases: Web of Science, PubMed, IEEE Xplore, ScienceDirect, and arXiv. The search string was designed to reflect four essential themes: The clinical condition (OSAHS), the signal type (snore or snoring), the data representation (spectrogram, Mel-spectrogram, wavelet scalogram, or image-based), and the algorithmic framework (deep learning, CNN, DNN, RNN, or transformer). Keywords were combined using Boolean logic to ensure comprehensive coverage. Only peer-reviewed journal articles, full-length conference papers, and reputable preprints written in English were considered. No restrictions were placed on geographical origin or clinical setting.
All articles were initially screened by title and abstract to exclude clearly irrelevant studies. The remaining records were then subjected to full-text review to assess methodological quality and inclusion eligibility. Studies were retained if they met the following criteria: (1) They used snoring sound signals as the primary input modality; (2) The signals were transformed into two-dimensional representations (e.g., spectrogram, Mel-spectrogram, wavelet scalogram); and (3) They employed a deep learning framework—such as CNN, DNN, RNN, or attention-based architectures—for snoring sounds classification, OSAHS patients detection, and AHI estimation. Exclusion criteria were defined as follows: (1) Studies only using handcraft linear and nonlinear acoustic features without graphical transformation; (2) articles relying exclusively on non-acoustic signals (e.g., ECG, SpO2); and (3) secondary literature such as review articles or editorials. There is no formal risk of bias assessment was conducted due to the nature of the included literature.
The screening process followed a rigorous multi-stage approach. After removal of duplicates, titles and abstracts were screened, followed by full-text evaluation. Two independent reviewers conducted the assessments, and any disagreements were resolved through discussion. The flow chart of the search strategy is presented in Figure 1. Out of an initial corpus of 205 retrieved records, a total of 14 studies were ultimately selected as meeting all inclusion criteria and were deemed sufficiently relevant to the focus of this review. These studies form the basis for subsequent synthesis and comparative analysis (Figure 1).
Figure 1
Flowchart of the study selection process.
Snoring based datasets
In the domain of snoring based OSAHS diagnosis, the availability of well-curated, labeled datasets forms a critical foundation for model development and evaluation. Variability in acoustic characteristics, due to patient physiology, obstruction severity, recording equipment, and environmental conditions, makes the quality and standardization of datasets a central concern. Table 1 summarizes representative open access datasets of snoring sounds applied in different classification tasks. Detailed descriptions are provided below.
The Snoring-Detection dataset provides 1000 short audio clips, evenly divided between snoring and non-snoring sounds, recorded in various background environments with a sampling rate of 16 kHz[22]. Although the age range of the subjects is not specified, this dataset is particularly valuable for developing lightweight classification models due to its clean binary labeling and diverse background noise inclusion.
The Infant Cry and Snoring Detection dataset focuses on infant audio recordings, containing both crying and snoring sounds[23]. Subjects are typically aged between 0 and 2 years. The dataset features multiple subsets, including weakly labeled, strongly labeled, and synthetic data, collected in indoor environments. Its design supports training and evaluation under different annotation conditions, making it suitable for early-stage anomaly detection research.
The PSG-Audio Corpus[24], curated collaboratively across several sleep centers, stands as one of the most comprehensive datasets for synchronized audio used in PSG research. It involves multi-channel audio streams, including throat microphones, ambient room microphones, and tracheal sensors, sampled at 48 kHz with full PSG synchronization (electroencephalogram, electrooculogram, electromyogram, ECG, airflow, etc.). Recordings cover over 212 patients in sleep lab settings. Apnea, hypopnea, snoring, and arousal events are annotated to American Academy of Sleep Medicine 2012 standards by board-certified technologists. Although the corpus has been referenced in benchmark studies for audio-based apnea detection, the snoring sounds and apnea-hypopnea events provided in this database are throughout the night and unlabeled. Researchers need to conduct further processing based on PSG data to study the relationship between snoring sounds and OSAHS.
The Snore-based Sleep Body Position Recognition dataset, developed by Xiao et al[25], is a snoring sound corpus collected under clinical PSG supervision for the purpose of body position recognition during sleep. It comprises audio recordings from 20 patients in a hospital-based sleep lab, synchronized with full-night PSG monitoring. Snoring events were captured using lavalier microphones placed 3 cm from the patient’s mouth, sampled at 32 kHz with 16-bit resolution, and recorded throughout natural sleep. Each snoring segment, ranging from 0.29 to 8.39 seconds, was annotated based on synchronized video and PSG-derived body position signals. Labels cover six positional classes including supine, prone, lateral, and head-tilted variants. A total of 7570 snoring samples are included in the database. Although the dataset has been used to benchmark transformer-based models for acoustic body position recognition, the snoring sounds remain unlabeled for apnea-related events. Further annotation and PSG-derived ground truth would be required to extend its use in OSAHS-related diagnostic tasks.
In addition to publicly available datasets, a significant portion of existing research relies on self-collected snoring sound recordings within controlled laboratory or clinical environments[26–29]. In these studies, researchers typically design customized recording protocols tailored to their specific experimental objectives, using a range of recording devices such as condenser microphones, throat microphones, or ambient sensors. The collected audio data are manually annotated, often through a combination of expert listening, PSG synchronization, and event-based labeling strategies. This approach enables precise control over subject selection criteria, recording conditions, and annotation granularity, allowing researchers to create datasets that are optimally suited to particular investigative goals, such as distinguishing different types of snoring events, detecting obstructive sleep apnea-related sounds, or analyzing snore temporal dynamics. However, the variability in data collection protocols and annotation standards among different research groups also introduces challenges for cross-study comparison and model generalization.
Although the number of private datasets continues to grow, their quality remains inconsistent and face accessibility and reproducibility barriers. There is no large-scale, labeled snoring sounds dataset specifically designed for studying the severity of OSAHS. Furthermore, differences in microphone specifications, sampling rates, and annotation criteria complicate cross-dataset benchmarking. Future efforts should prioritize the development of open, large-scale, multi-modal snore databases with standardized recording protocols, demographic diversity, and event-level annotations synchronized with PSG references (Table 1).
Graphical representation methods
The transformation of one-dimensional acoustic waveforms into two-dimensional image-like representations forms is the foundation of image-based deep learning models for OSAHS diagnosis. Among the various approaches developed for this purpose, four categories have proven especially effective: Time-domain image embedding, spectrograms, Mel-spectrograms, and scalograms. Each representation offers unique advantages in preserving acoustic information and enhancing model performance.
The time-domain image embedding method reshapes raw amplitude values into a two-dimensional matrix without applying frequency decomposition[30]. Let x(t) be the waveform sampled at discrete times; a visual representation can be constructed by segmenting x(t) into patches of fixed length N, and stacking them as rows of a matrix:
Alternatively, some models apply a set of 1D convolutional layers to extract hierarchical time-domain features, which are then projected into 2D maps through learned kernels. This approach retains the raw signal morphology and is especially suited to unsupervised autoencoder structures or raw-signal CNN front ends.
The spectrograms are construct by short-time Fourier transform (STFT), which is one of the most commonly used techniques in audio signal analysis[31,32]. It decomposes a waveform into localized time–frequency components by applying a sliding window Fourier transform:
Where w (t - τ) is a window function centered at time τ. The resulting complex-valued matrix yields a spectrogram when the magnitude is plotted as an intensity map. Spectrograms offer robust representations of rhythmic and harmonic content, making them well suited for distinguishing typical snoring patterns from other respiratory anomalies.
The Mel-spectrogram further processes the STFT by converting the linear frequency scale into the Mel scale, which mimics human auditory perception[33]. Frequencies ƒmel are mapped as:
The STFT magnitude spectrum is passed through a triangular Mel filter bank. The resulting Mel spectrum is typically log-compressed for improved visual contrast. Compared to linear spectrograms, Mel-spectrograms offer more compact representations and are less sensitive to high-frequency noise, making them ideal for mobile and resource-constrained environments.
The continuous wavelet transform (CWT) provides a multi-resolution analysis that captures both transient and sustained components in the snore waveform[34–37]. Unlike STFT, which uses a fixed window size, CWT adapts its resolution to different frequency bands. It is defined as:
where a and b denote the scale and translation parameters. Ψ(t) is the wavelet function. The resulting scalogram encodes the temporal evolution of frequency components and has been widely used for its ability to highlight abrupt changes in acoustic energy—features often associated with apnea-related snore interruptions.
All of the aforementioned representations are typically standardized into square image formats (e.g., 224 × 224 or 256 × 256 pixels), normalized for amplitude and intensity, and formatted in grayscale or red-green-blue depending on the model input requirement. Preprocessing pipelines often include denoising, dynamic range compression, and silence removal. In addition, data augmentation techniques such as time-shifting, frequency masking, and mix up are commonly employed to improve robustness and generalization, particularly when datasets are limited in size or class balance. These graphical transformations serve not only as model inputs but also as interpretable visual artifacts that can aid clinicians in understanding and trusting model decisions. The choice of representation can significantly affect classification performance and interpretability in different clinical tasks, such as binary snoring detection, OSAHS patients classification with different severities, and snoring sounds classification of different sleep stages.
Deep learning architectures
Deep learning models applied to image-based snoring sounds analysis have demonstrated remarkable progress in recent years, outperforming traditional machine learning approaches across a wide range of tasks, including snoring sounds detection, apnea-hypopnea event localization, and OSAHS severity estimation. These models leverage the structured nature of transformed acoustic images to extract complex spatiotemporal patterns. This section presents a detailed overview of five major classes of deep learning architectures, emphasizing their internal mathematical formulations and suitability for graphical snore input modeling.
CNN
CNN serves as the backbone of most image-based snoring classification systems, which is composed of five basic layers, including input layer, convolution layer, activation function, pooling layer, and fully-connected layer[38–43]. Figure 2 display the detailed structure of CNN. These networks are specifically designed to learn spatial hierarchies in structured inputs such as spectrograms, Mel-spectrograms, or scalograms. The core component of a CNN is the convolution operation, which is applied to extract local features in the input image. The feature map G is obtained by the convolution layer by the expression:
Figure 2
The structure of convolutional neural network.
where 1 ≤ i ≤ ni, ni is the number of convolution kernels in a layer. x is the input image. k and b are the kernel function and bias respectively. The activation functions can be selected as rectified linear units, which is expressed as:
Pooling layers down sample the spatial dimensions while preserving dominant features. The maximum pooling and average pooling are usually for pooling layer. The final layer is equipped with a fully connected layer, which produces the output of the whole CNN. In the context of snoring-based diagnosis, CNNs are ideal for capturing apnea-related snoring sounds which were characterized with short-duration frequency modulations and time-varying energy burst. CNN has been built on VGG16, ResNet and EfficientNet architectures, having shown high performance in snoring sounds classification and OSAHS severity detection. However, traditional CNNs treat input frames independently and thus lack temporal awareness, which is a limitation addressed by sequential models (Figure 2).
RNN
RNN is designed to handle sequential data, making them particularly suited to snoring detection tasks where temporal dynamics across snoring episodes are informative[44]. Unlike CNNs, which model static features, RNNs retain a hidden memory state that evolves over time. The hidden node output ht is obtained by the previous unit ht-1and current input xt:
Standard RNNs struggle with long-term dependencies due to vanishing gradients. To address this, Long Short-Term Memory (LSTM) networks introduce gated memory mechanisms, which allows time steps to be passed further[38,45,46]. The memory cell includes three main gates, including an input gate, a forget gate, and an output gate, which facilitates the process of learning. The update of the cell can be expressed as follows:
While CNNs are powerful at learning spatial features and LSTMs excel at temporal modeling, the fusion of the two algorithms allows for spatiotemporal feature integration. In CNN–RNN hybrid architectures, CNN layers act as encoders to extract low-dimensional visual descriptors from each time window which are then sequentially fed into an RNN[38,46,47]. Such designs exploit CNNs’ ability to capture frequency–energy patterns across local patches while allowing the RNN to model transitions over time. Studies using CNN–LSTM hybrids have reported superior accuracy in multi-class OSAHS severity prediction and in segment-level apnea classification. These models are particularly well suited to long-duration overnight recordings segmented into uniform temporal blocks.
Transformer
The Transformer architecture eliminates recurrence and instead relies on self-attention mechanisms to model dependencies across entire sequences[48–51]. This is particularly valuable in apnea detection where temporal events are irregularly spaced. In Vision Transformer, spectrograms are divided into patches and linearly embedded, enabling the model to learn global context from positional interactions.
Transformer-based snore models outperform traditional RNNs in severity regression and multi-apnea-type classification, especially under noisy or irregular signal conditions. Hybrid CNN–transformer models have also been explored, where CNN layers extract local features which are then passed into transformer blocks to capture global relationships across time or frequency axes.
Evaluation metrics
Evaluation of deep learning models for snoring sounds classification and OSAHS diagnosis depends critically on the choice of performance metrics and the diversity of benchmark datasets used during validation. Classification tasks and regression tasks emphasize different aspects of predictive performance and thus require distinct evaluation frameworks. For classification task, accuracy (Acc), specificity (Spe), precision (Pre), sensitivity (Sen), and F1 score are applied to evaluate the performance of the model[52-54].
where TP, TN, FP, and FN denote true positives, true negatives, false positives, and false negatives respectively. In addition, the area under the receiver operating characteristic curve provides a threshold-independent measure of the model’s discrimination capability.
For regression tasks, particularly in continuous apnea severity prediction such as AHI estimation, different metrics are adopted to quantify the deviation between predicted and true values. The mean squared error (MSE)[55], which represents the average magnitude of absolute prediction errors, is defined as:
Where yi are ŷi the true AHI value and predicted AHI value respectively. is the mean value of true value. Coefficient of determination (R² Score) evaluates the proportion of variance in the target variable that is predictable from the model and is calculated by:
RESULTS
This section synthesizes experimental findings from 14 studies primarily categorized into two research directions: Snoring sound classification and OSAHS diagnosis. Based on model inputs, algorithmic structure, and clinical task formulation, we analyze and compare model performances using results summarized in Tables 2 and 3.
Table 2 The performance of snoring sounds detection based on different works.
In this section, nine works are concluded for snoring sounds identification using image-based features and deep learning structures. The detailed information about these studies is summarized in Table 2, which includes information about the authors, datasets, image types, models, classification tasks, and main results. The studies used various audio datasets collected from different environments, such as clinical sleep study lab and home-based smartphone recordings. For instance, Hong et al[56] used 200 minutes of smartphone audio data from participants. Ye et al[57] used whole night sleep recordings from 30 subjects. There is no open access and labeled snoring sounds dataset that can be used for exploring the difference between snoring sounds and non-snoring sounds, which leads to the results of these studies being non-reproducible. In terms of feature representation, these studies mainly focused on extracting image-based features from the audio data, such as time-domain waveforms, spectrograms, Mel-spectrograms, and wavelet scalogram. These features are crucial for representing the time-frequency characteristics of snoring sounds and enhancing the performance of deep learning models. The majority of existing studies rely on a single time-frequency representation. To better exploit the complementary information among different image representation, Ye et al[57] explored multi-channel spectrograms, which integrated various single-channel features such as spectrogram, Mel-spectrogram, and scalogram into a fused spectrogram. This method outperformed traditional single spectrograms, achieving an accuracy of 94.18%, which highlighted the potential of using multi-channel spectrograms to capture more diverse and relevant features of snoring sounds.
There are different deep learning classification models applied in the identification task, but most studies relied on CNNs due to their ability to learn spatial hierarchies in image data. Some studies employed hybrid architectures combining CNNs with other models such as RNNs and LSTMs[58-60]. For example, Jiang et al[60] used a combination of CNNs, LSTMs, and DNNs, achieving 95.00% accuracy in classifying snoring sounds. Li et al[61] applied a hybrid 1D-2D CNN model that combined 1D CNN for processing raw signals and 2D CNN for analyzing images derived from visibility graph transformations, achieving an accuracy of 89.3%. These findings underscore the efficacy of deep learning models, especially CNN-based architectures, in detecting snoring events with high accuracy. The results also highlight the importance of feature extraction methods, such as Mel-spectrograms and harmonic spectrograms, which capture crucial time-frequency information from the audio signals. An important consideration in real-world applications of snoring detection is the placement of the recording microphones. Xie et al[62] examined the impact of microphone placement on snoring sounds detection performance. The best accuracy (95.9%) was observed when the microphone was placed 70 cm above the subject's head, while the worst (94.4%) was observed with the microphone placed 130 cm above the subject's head. This result suggests that snoring detection models can be robust to variations in microphone placement, which is a valuable finding for practical applications in home-based sleep monitoring systems.
OSAHS diagnosis
Due to the frequent occurrence of apnea-hypopnea events during sleep, the shape of the upper airway of OSAHS patients changes repeatedly, resulting in the generation of various of snoring sounds throughout the sleep. The five studies were reviewed for the application of deep learning frameworks based on image representation in the classification of snoring sounds to diagnose OSAHS patients. The detection and classification of OSAHS patients based on snoring sounds has been significantly enhanced through the use of advanced time-frequency graphical representations combined with hybrid deep learning models. Several studies have explored various approaches, highlighting the importance of Mel-spectrograms, spectrograms, and scalograms for capturing both spectral and temporal features of snoring sounds in different stages of apnea-hypopnea events. These models have demonstrated substantial performance improvements, providing a promising solution for non-invasive OSAHS screening and severity classification[63].
Table 3 summarized the detailed information about the reviewed studies. The majority of the studies employed Mel-spectrograms due to their effectiveness in representing frequency features relevant to snoring sounds. For instance, Zhang et al[64] utilized a CNN-LSTM hybrid model for multiclass classification of snoring sounds, which classified OSAHS patients into four severity levels: Normal, mild, moderate, and severe. This approach achieved an accuracy of 87.4%, demonstrating the utility of sequential models in capturing subtle transitions in snoring patterns associated with OSAHS severity. The study underscores the advantage of using hybrid models that combine CNN’s spatial feature extraction with LSTM’s temporal sequence learning for better handling of snoring's temporal dependencies. Similarly, Ding et al[46] applied a VGG19-LSTM hybrid model to classify apnea events related snoring sounds and normal snoring sounds during the whole night. Their work further explored the correlation between the apnea events related sounds and AHI of OSAHS. Cheng et al[65] constructed a BiLSTM-based model using multi-scale Mel-spectrogram patches, achieving an accuracy of 88.9% for severity classification. These models demonstrate the potential for real-time, low-cost monitoring of OSAHS in clinical and home settings. These studies have explored multi-branch hybrid models that incorporate various network architectures, including CNN, LSTM, to jointly capture both spectral texture and temporal progression in snoring sounds. The multi-branch design improved the model’s ability to extract both fine-grained features from snoring signals and dynamic temporal patterns related to apnea events[66,67].
DISCUSSION
The effectiveness of deep learning in snoring sounds analysis mainly deep on the image representation and model architecture. The choice of acoustic-to-visual transformation significantly influences the performance of deep learning models in snoring detection and OSAHS diagnosis task. spectrograms offer fine temporal resolution but suffer from limited frequency localization[17,20,68]. In contrast, Mel-spectrograms provide a perceptually inspired compression, making them suitable for lightweight models and noisy conditions. Scalogram deliver superior time–frequency granularity and are especially useful in detecting abrupt breathing disruptions, which computationally more expensive and sensitive to parameter selection. Recent studies have demonstrated that no single graphical representation universally outperforms others across all tasks. Instead, the suitability of each image type depends on the application. This highlights the need for adaptive representation learning methods that can dynamically select or fuse visual modalities based on task demands and input characteristics.
The comparative performance analysis reveals distinct strengths among different models. CNN-based models outperform in spatial pattern recognition from acoustic images, especially in short-segment snoring sounds detection. They offer fast training, interpretable filters, and efficient deployment. However, CNNs are limited in modeling temporally extended phenomena such as apnea–hypopnea cycles. Sequential models such as LSTM and BiLSTM capture temporal dependencies and yield improved performance in the OSAHS severity prediction tasks. However, they are often memory-intensive and prone to overfitting, especially on small datasets. Transformer-based architectures introduce a new paradigm by replacing recurrence with global attention mechanisms. Their ability to model long-range dependencies across image sequences makes them particularly suitable for AHI estimation, although their training requires significant computational resources and large datasets.
Future architecture designs should focus on integrating task-aware architectural modules. For instance, combining CNNs for spatial abstraction with attention modules for cross-time reasoning in a modular and scalable fashion[55,69]. Fusion strategies, whether at the representation level (e.g., STFT + Mel) or architectural level (e.g., CNN + Transformer), offer meaningful improvements in generalizability, robustness, and decision confidence. Fused models capture complementary perspectives. While one input may outperform at frequency resolution, another may provide noise-resilience. While one model may detect periodic patterns, another may capture transient disruptions. Despite these benefits, fusion models present several practical challenges. They increase computational load and inference latency, which complicate model interpretability, and often require sophisticated hyperparameter tuning. Additionally, simple concatenation of features may lead to redundancy or performance saturation. Addressing these limitations requires the development of attention-based adaptive fusion, modality dropout training, and dynamic routing mechanisms that allow models to selectively weigh representations or sub-networks during inference.
Despite substantial progress, several challenges remain before snore-based image diagnosis systems can be clinically viable[19,20,70–72]. First, data availability and standardization remain a significant problem. Many datasets are institutionally restricted, lack detailed annotations, differ in recording quality and device setup, hindering cross-study comparability. Creating large-scale, open-access, and event-aligned datasets is a prerequisite for reproducibility. Second, model generalization across populations, languages, sleep stages, and recording environments is not sufficient. Future systems must incorporate domain adaptation, multi-condition training, and robust augmentation pipelines to handle real-world variability. Third, interpretability and clinical integration of the diagnosis models remain critical. Models must not only provide accurate predictions but also offer transparent reasoning to build clinician trust. Integration with existing screening workflows, through mobile apps, home devices, or cloud-based APIs, requires lightweight yet explainable architectures. Finally, semi-supervised and self-supervised learning based on vast amounts of unlabeled snore data, will be essential to scale deployment while reducing labeling costs. Cross-modal training, federated learning, and continual adaptation across devices and users represent exciting frontiers.
CONCLUSION
The primary aim of this study was to systematically review deep learning-based approaches for snoring sound classification and OSAHS diagnosis using graphical representations. Three main types of graphical transformations were identified across studies: Time-frequency domain (spectrograms), perceptually scaled frequency domain (Mel-spectrograms), and multi-resolution domain (scalograms). These graphical forms enable the translation of complex snoring acoustics into visual patterns accessible to convolutional and sequential neural architectures. Deep learning models, predominantly CNN-based for event classification and hybrid CNN–LSTM or CNN–Transformer mode, have demonstrated high accuracy for snoring sounds classification, OSAHS patients detection and clinically acceptable AHI estimation errors. Lightweight models and attention mechanisms have further enhanced model efficiency and interpretability in challenging recording environments. From the analysis of datasets, it is evident that the field faces limitations in terms of publicly available, large-scale, and high-fidelity snore-specific databases. Variability in microphone quality, recording conditions, and annotation standards across datasets hampers the generalizability of current models.
Future work should prioritize the construction of unified, multimodal datasets adhering to AASM-based annotation standards. In addition, feature-level fusion of multiple graphical representations and the deployment of explainable machine learning models will be critical for achieving clinician trust and broader adoption. Finally, systematic exploration of parameter tuning strategies, lightweight deployment-ready architectures, and big data integration for large-scale sleep disorder screening represent promising directions. By addressing these gaps, future research can pave the way toward non-invasive, accessible, and reliable OSAHS diagnostic systems based on snoring sound analysis.
Amiriparian S, Gerczuk M, Ottl S, Cummins N, Freitag M, Pugachevskiy S, Baird A, Schuller B. Snore Sound Classification Using Image-Based Deep Spectrum Features.Interspeech. 2017;3512-3516.
[PubMed] [DOI] [Full Text]
Liu Q, Song L, Xu D, Long Y.
ICSD: An open-source dataset for infant cry and snoring detection. 2024 Preprint. Available from: arXiv:2408.10561.
[PubMed] [DOI] [Full Text]
Xiao L, Yang X, Li X, Tu W, Chen X, Yi W, Lin J, Yang Y, Ren Y. A Snoring Sound Dataset for Body Position Recognition: Collection, Annotation, and Analysis.Interspeech. 2023;5416-5420.
[PubMed] [DOI] [Full Text]
Qian K, Janott C, Zhang Z, Heiser C, Schuller B.
Wavelet features for classification of vote snore sounds. 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 2016: 221-225.
[PubMed] [DOI] [Full Text]
Razavian AS, Azizpour H, Sullivan J, Carlsson S.
CNN Features Off-the-Shelf: An Astounding Baseline for Recognition. 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, United States, 2014: 512-519.
[PubMed] [DOI] [Full Text]
Naruse Y, Tada H, Satoh M, Yanagihara M, Tsuneoka H, Hirata Y, Ito Y, Kuroki K, Machino T, Yamasaki H, Igarashi M, Sekiguchi Y, Sato A, Aonuma K. Concomitant obstructive sleep apnea increases the recurrence of atrial fibrillation following radiofrequency catheter ablation of atrial fibrillation: clinical impact of continuous positive airway pressure therapy.Heart Rhythm. 2013;10:331-337.
[RCA] [PubMed] [DOI] [Full Text][Cited by in Crossref: 165][Cited by in RCA: 199][Article Influence: 14.2][Reference Citation Analysis (0)]
Nguyen MT, Huang JH.
Snore Detection Using Convolution Neural Networks and Data Augmentation. In: Long BT, Kim HS, Ishizaki K, Toan ND, Parinov IA, Kim YH, editors. Proceedings of the International Conference on Advanced Mechanical Engineering, Automation, and Sustainable Development 2021 (AMAS2021). AMAS 2021. Lecture Notes in Mechanical Engineering. Cham: Springer, 2021.
[PubMed] [DOI] [Full Text]
Lim SJ, Jang SJ, Lim JY, Ko JH. Classification of snoring sound based on a recurrent neural network.Expert Systems Appl. 2019;123:237-245.
[PubMed] [DOI] [Full Text]
Huang Y, Chen L, Huang Q.
Fine-Grained Detection of Apnea-Hypopnea Events Based on Transformer Network in Audio Recordings. 2023 8th International Conference on Intelligent Computing and Signal Processing (ICSP), Xi'an, China, 2023: 580-585.
[PubMed] [DOI] [Full Text]
Ding L, Peng J. Automatic classification of snoring sounds from excitation locations based on prototypical network.Appl Acoust. 2022;195:108799.
[PubMed] [DOI] [Full Text]
Wang C, Peng JX, Zhang XW. A Classification Method Related to Respiratory Disorder Events Based on Acoustical Analysis of Snoring.Arch Acoust. 2023;45:141-151.
[PubMed] [DOI] [Full Text]
Liu W, Zhang S, Zhou L.
High-precision snore detection method based on deep learning. Fifth International Conference on Mechatronics and Computer Technology Engineering (MCTE 2022), Chongqing, China, 2022.
[PubMed] [DOI] [Full Text]
Li R, Li W, Yue K, Li Y. Convolutional neural network for screening of obstructive sleep apnea using snoring sounds.Biomed Signal Process Control. 2023;86:104966.
[PubMed] [DOI] [Full Text]
Zhang J, Zhang Q, Wang Y, Qiu C.
A real-time auto-adjustable smart pillow system for sleep apnea detection and treatment. Proceedings of the 12th international conference on Information processing in sensor networks. New York: Association for Computing Machinery, 2013: 179-190.
[PubMed] [DOI] [Full Text]
Provenance and peer review: Invited article; Externally peer reviewed.
Peer-review model: Single blind
Specialty type: Radiology, nuclear medicine and medical imaging
Country of origin: China
Peer-review report’s classification
Scientific Quality: Grade A, Grade B
Novelty: Grade A, Grade B
Creativity or Innovation: Grade A, Grade B
Scientific Significance: Grade A, Grade B
Open Access: This article is an open-access article that was selected by an in-house editor and fully peer-reviewed by external reviewers. It is distributed in accordance with the Creative Commons Attribution NonCommercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited and the use is non-commercial. See: https://creativecommons.org/Licenses/by-nc/4.0/
P-Reviewer: Chen JY, Researcher, China S-Editor: Liu H L-Editor: A P-Editor: Lei YY
















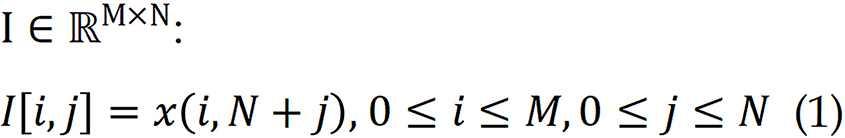
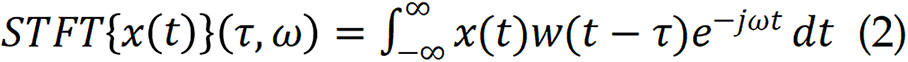
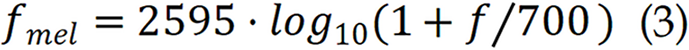
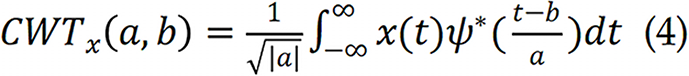
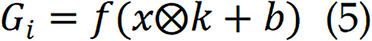

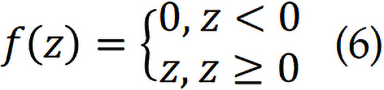
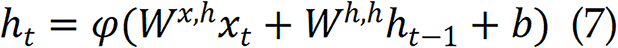
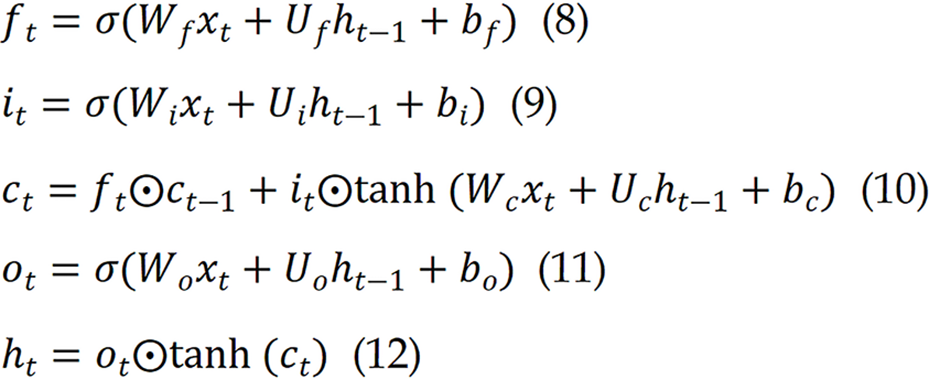

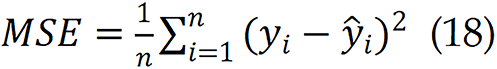
 is the mean value of true value. Coefficient of determination (R² Score) evaluates the proportion of variance in the target variable that is predictable from the model and is calculated by:
is the mean value of true value. Coefficient of determination (R² Score) evaluates the proportion of variance in the target variable that is predictable from the model and is calculated by: